系统概览(System Overview)
连接服务器后,系统概览页自动拉取运行时指标并每 10 秒刷新,提供对节点健康度的实时洞察。
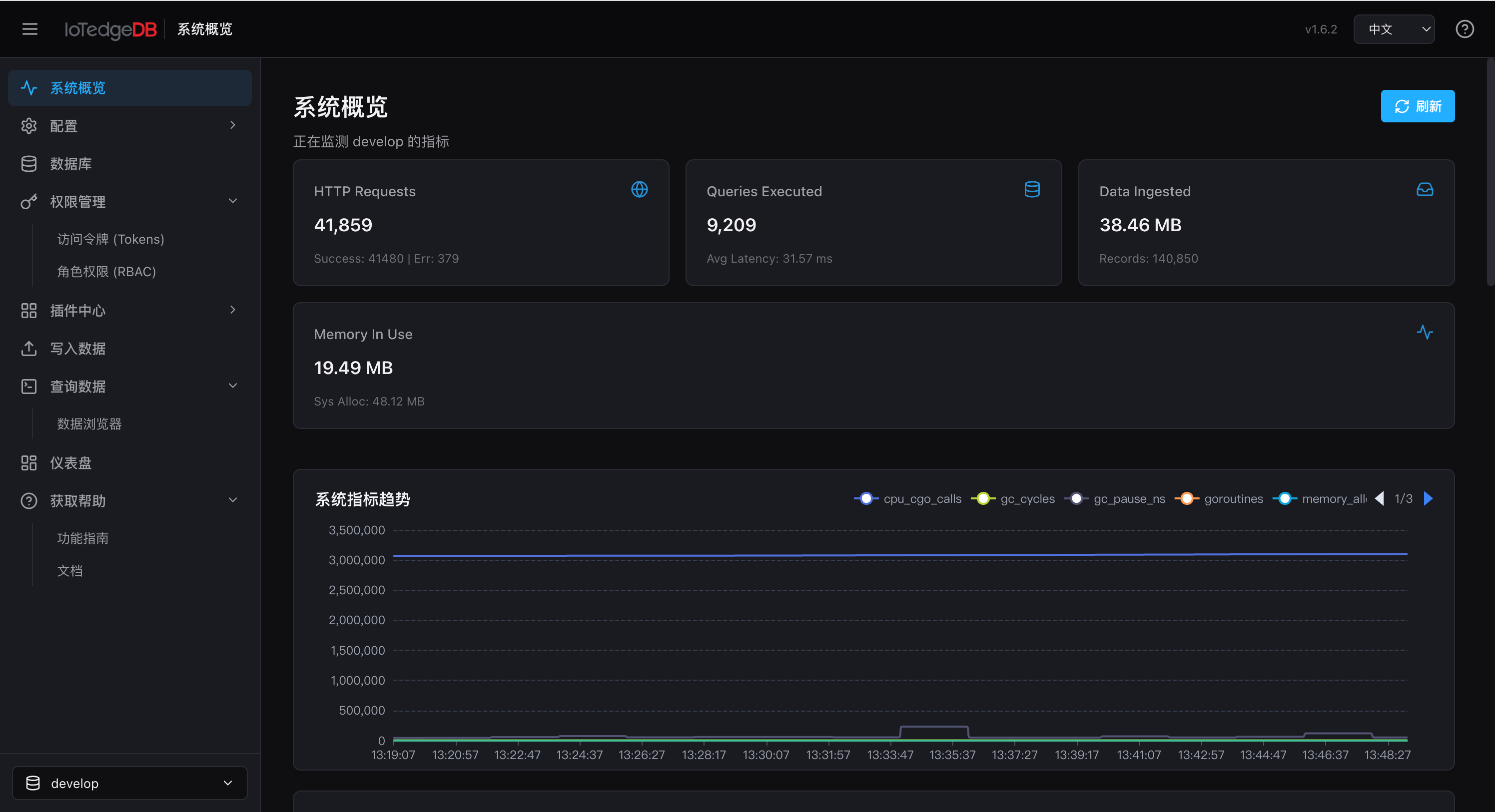
顶部高亮卡片
页面顶部展示 4 个关键统计:HTTP 请求数、查询执行次数、数据摄入量、当前内存占用。一目了然地掌握节点负载。
时序趋势图
三张 ECharts 折线图分别展示系统指标趋势、API 性能趋势、数据库操作趋势,通过时间轴直观反馈 CPU、吞吐量和延迟的波动。
高级指标面板
15 个可折叠分组深入到底层细节:
- 系统与环境:Go 版本、运行时长、CPU 核数、Goroutine 数
- 内存与 GC:堆内存、系统内存、GC 周期与停顿
- HTTP 请求:请求总数、错误数、延迟
- 查询引擎:执行次数、返回行数、活跃查询
- 数据库连接:打开数、空闲数、使用中
- 认证与审计:认证请求、缓存命中率、审计事件
- 数据摄取:字节数、批次、行协议与 MsgPack 解析
- 存储引擎:读写次数与字节数
- 压缩:压缩任务数、文件数、读写量
- WAL:记录保留与恢复
- MQTT 协议:连接数、消息数、字节数
- 治理与限制:活跃策略、额度耗尽、限流
- 复制:序列差距、丢弃条目
每个分组内以统计卡片网格展示具体数值,折叠态不占用视觉空间,展开即见全貌。
服务器管理(Servers)
所有视图的基础——必须连接至少一台 IotEdge DB 服务器才能使用平台功能。
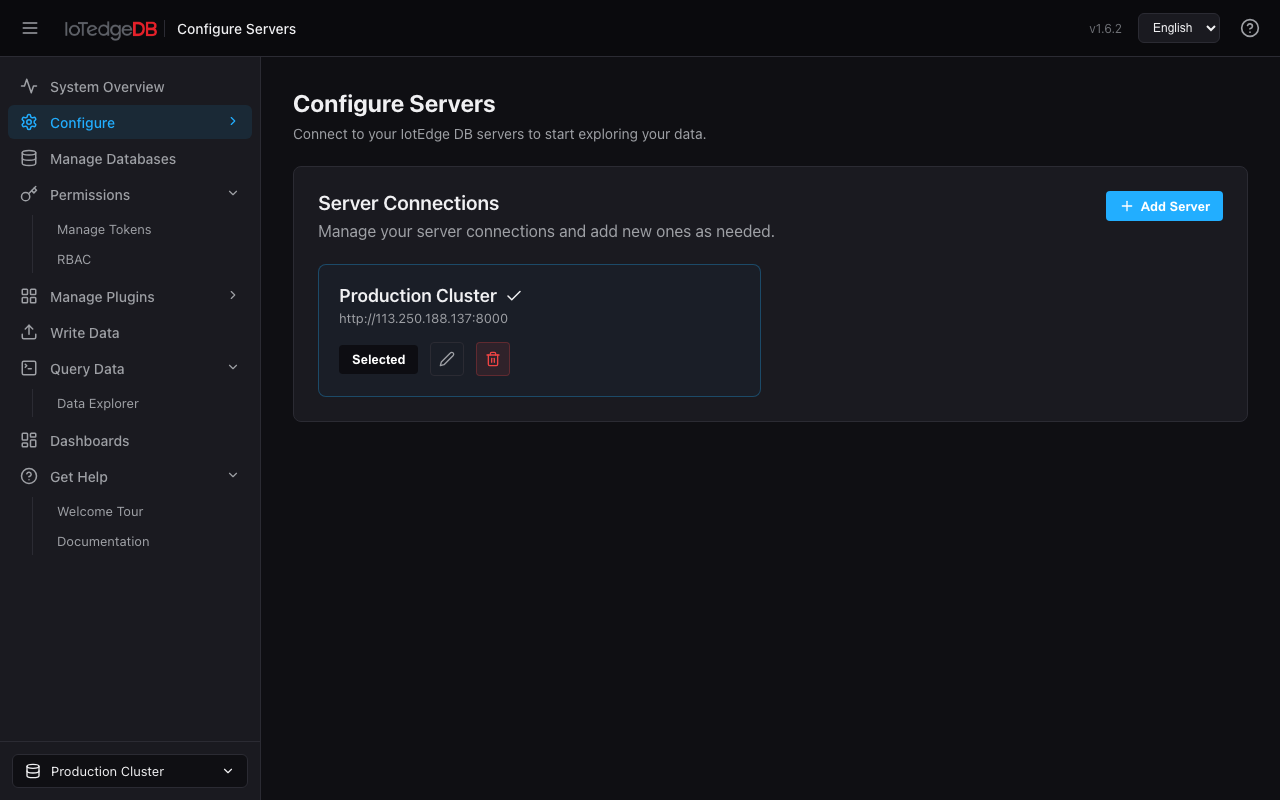
功能要点
- 添加服务器:填写服务器名称、URL(支持 http/https 协议选择)、Token(带显隐切换的安全输入框)
- 切换服务器:点击卡片即可切换当前活动服务器,所有视图实时同步
- 编辑 / 删除:随时修改连接信息或移除不再使用的服务器
- 持久化存储:连接信息存储在浏览器 localStorage,刷新不丢失
侧边栏底部也提供快速服务器切换器,无需跳转页面即可更换工作上下文。
数据库管理(Databases)
以卡片网格形式管理数据库的全生命周期。
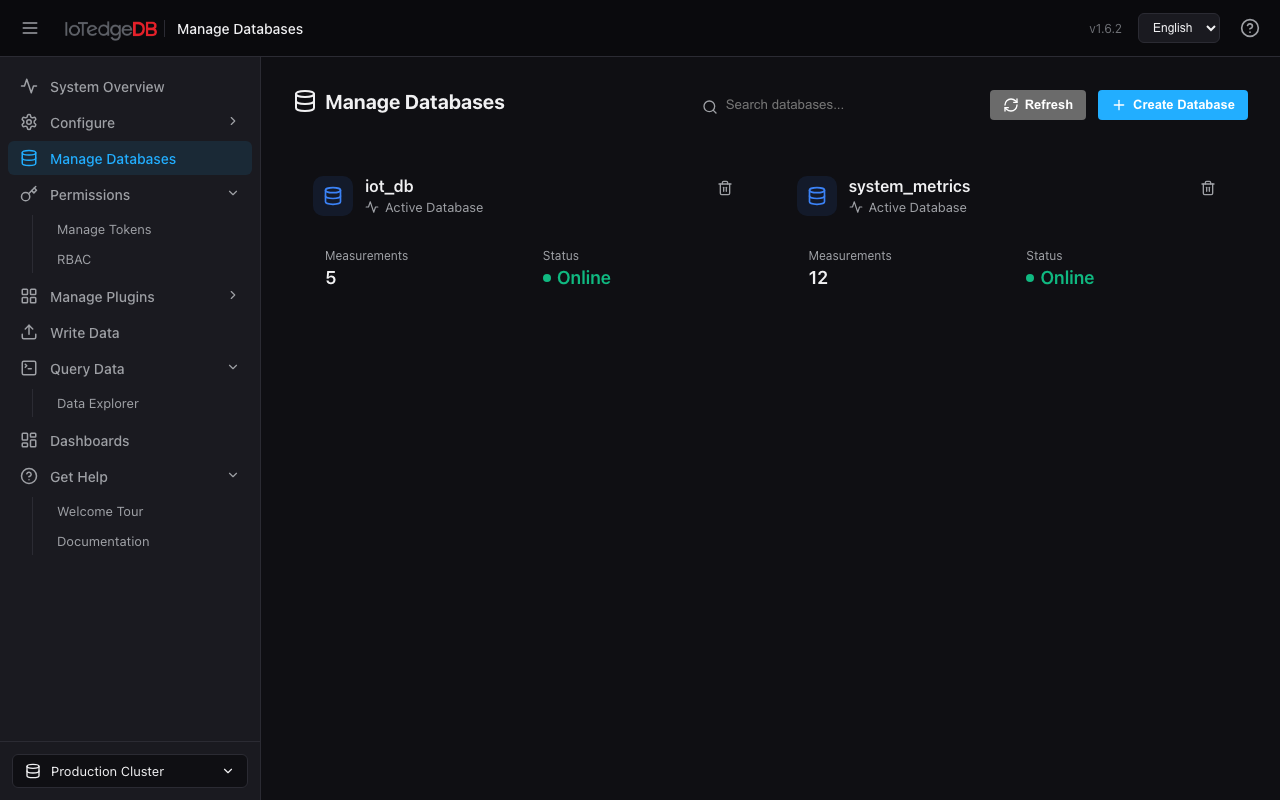
功能要点
- 搜索过滤:按数据库名模糊搜索
- 创建数据库:弹出表单输入名称,支持下划线、字母和数字
- 删除数据库:二次确认弹窗,明确提示"此操作无法撤销"
- 统计信息:每张卡片展示 Measurement 数量和在线状态
数据库创建后,即可在其他模块(数据探索器、写入数据、连续查询)中选取使用。
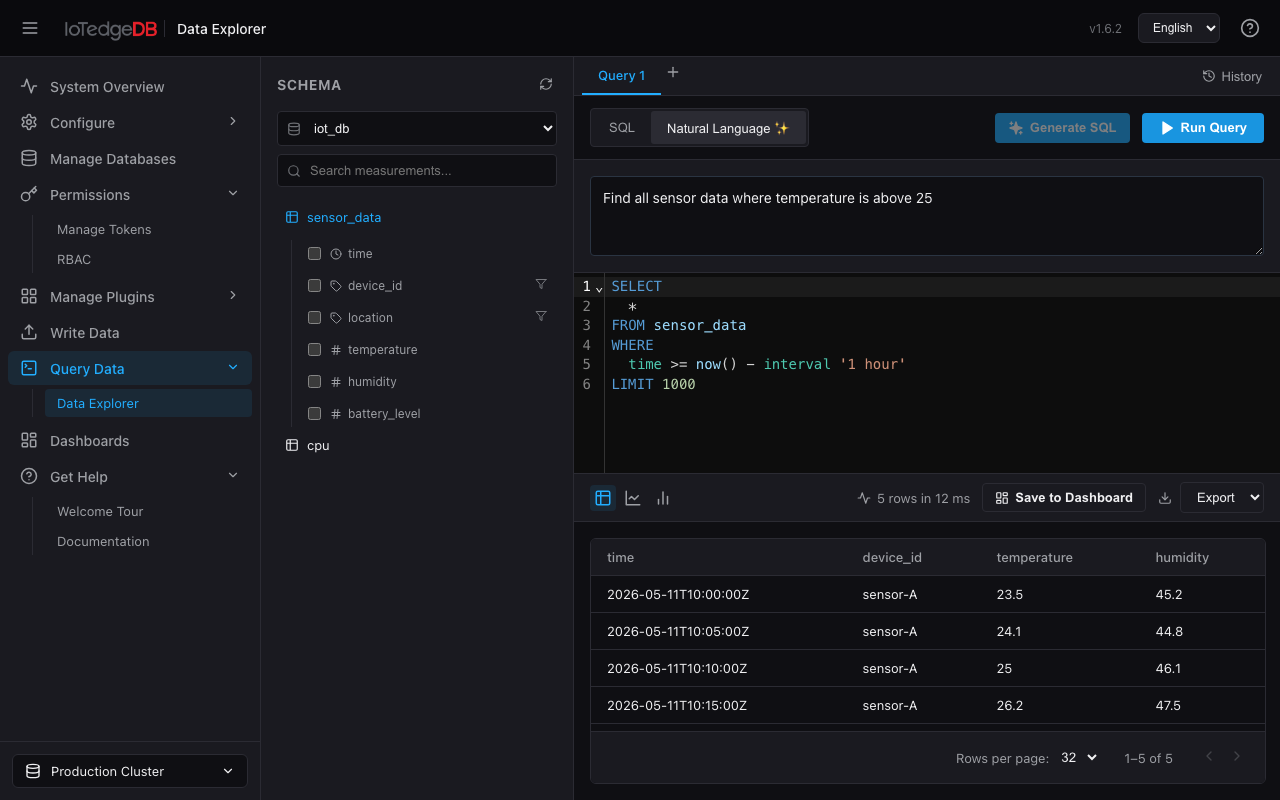
数据探索器(Data Explorer)
平台的核心查询交互工具,支持 SQL 编辑、自然语言生成 SQL、可视化分析和 Dashboard 集成。
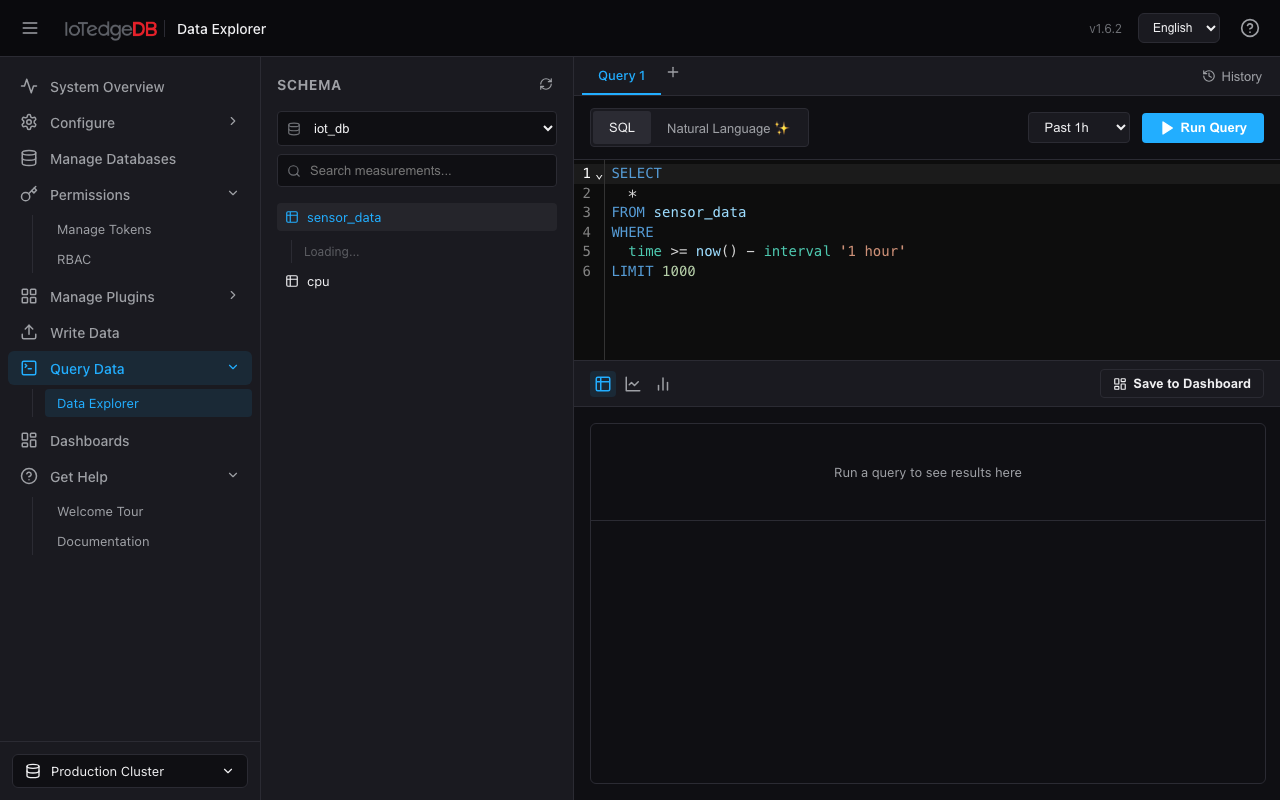
双面板布局
左侧 Schema 浏览器:以树形结构展示数据库和 Measurement。展开任意 Measurement 可将列按 time / tag / field 分类展示。勾选列自动生成 SELECT 子句,tag 列还支持筛选按钮——自动拉取 DISTINCT 值并以复选框展示,选中后动态注入 WHERE 条件。
右侧查询工作区:多 Tab 页并行,每个 Tab 拥有独立的 SQL、结果集和可视化状态。
SQL 编辑器
基于 CodeMirror 6 + @codemirror/lang-sql,集成 Schema 感知补全:选中数据库后,表名和列名会自动加入补全字典,输入时弹出智能提示。
-- 输入 "SELECT " → 自动列出所有列名
-- 输入 "FROM " → 自动列出所有 Measurement
SELECT device_id, temperature, humidity
FROM sensor_data
WHERE time > now() - interval '1 hour'
AND device_id IN ('sensor-a', 'sensor-b')
时间范围选择器:提供 15m、1h、6h、24h、7d、30d 快捷选项及自定义起止时间。选区变更后 SQL 中的时间条件自动替换,不影响其他 WHERE 子句。
NL2SQL:自然语言生成 SQL
切换到 Natural Language 模式,用日常语言描述需求,点击 "Generate SQL":
- 自动遍历数据库所有 Measurement,执行
SELECT * LIMIT 1解析列结构 - 将 Schema 信息拼接为 System Prompt
- 调用已配置的 AI 大模型(OpenAI 兼容
/chat/completions接口) - 剥离 Markdown 标记,将纯净 SQL 填入编辑器
输入:
查询最近 1 小时温度超过 80 度的设备 ID 和对应温度值
生成 SQL:
SELECT device_id, temperature
FROM sensor_data
WHERE time > now() - interval '1 hour'
AND temperature > 80
ORDER BY time DESC
支持的 AI 提供商:OpenAI、DeepSeek、通义千问、智谱 GLM、Moonshot (Kimi)、豆包、腾讯混元、百度千帆、讯飞星火、LM Studio(本地模型)。
结果可视化
查询结果支持三种呈现方式:
- 表格:分页(16 / 32 / 128 行/页),显示总行数和执行耗时
- 折线图 / 柱状图:ECharts 渲染,自动识别数值列作为 Y 轴、时间列作为 X 轴。支持悬停详情、图例切换、区域缩放
查询历史与收藏
右侧抽屉面板 分为 History 和 Favorites 两个 Tab。最近 50 条查询自动记录,点击即可回填到编辑器。收藏夹独立存储,不受历史清除影响。数据通过 localStorage 持久化。
导出与 Dashboard 集成
- 数据导出:CSV 或 JSON 一键下载
- 保存到仪表盘:选择 Cell 名称、可视化类型和目标 Dashboard,SQL 查询和数据库上下文随之一同保存,在 Dashboard 中自动渲染
写入数据(Write Data)
提供三种数据导入方式的统一入口。
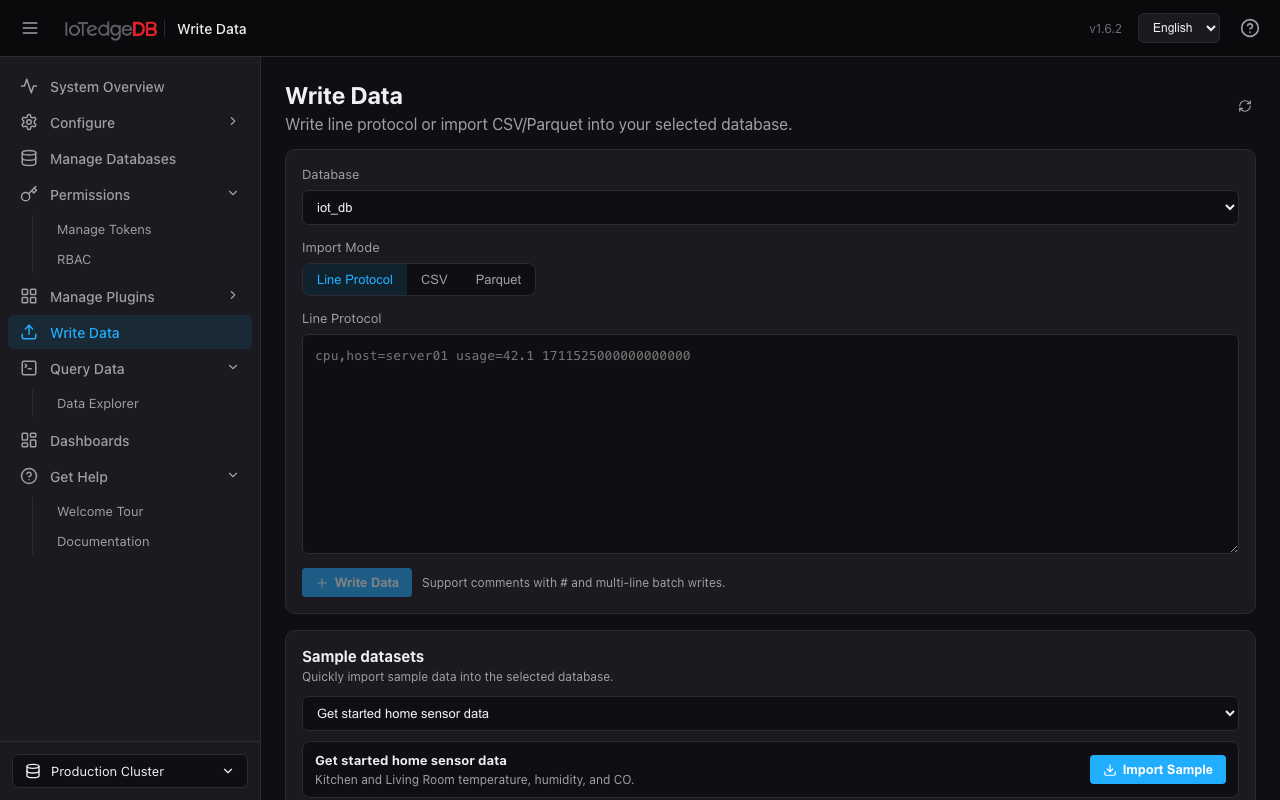
行协议(Line Protocol)
在 monospace 文本框中直接粘贴行协议数据,自动校验格式(检查 measurement 名、tag 集、field 集)。支持以 # 开头注释和多行批量写入。写入时按每 500 行切块发送,单块失败自动重试 2 次。
CSV / Parquet 文件导入
选择目标数据库和 Measurement 后,上传本地 CSV 或 Parquet 文件,通过 HTTP multipart/form-data 发送到服务端导入。
示例数据集
内置 6 组示例数据,一键导入到当前数据库:
- 传感器数据
- 传感器操作日志
- 湾区天气
- 风力数据
- 比特币价格数据
- 随机数生成
右侧面板实时展示当前数据库的 Measurement 列表,导入完成后立即刷新。
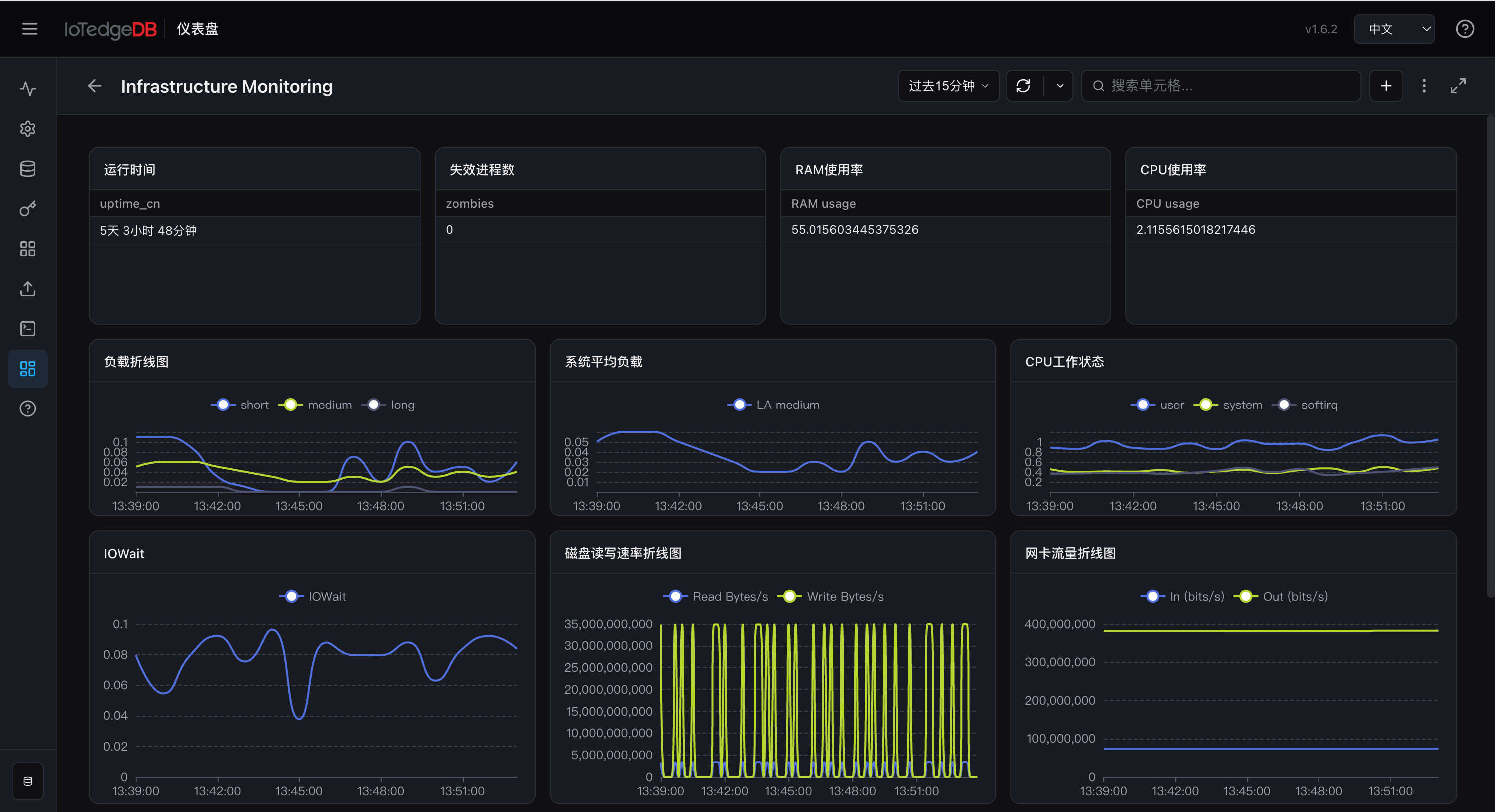
仪表盘(Dashboards)
自定义可视化仪表盘构建器,支持拖拽布局和多源查询。
列表视图
卡片网格展示所有仪表盘,支持搜索、新建、编辑名称/描述、删除。每个卡片显示 Cell 数量。
导入/导出:仪表盘以 JSON 格式导入导出,便于备份和团队共享。导入时自动重新生成 ID 避免冲突。
详情视图(拖拽编辑)
进入单个仪表盘后:
- 时间范围:全局时间选择器(15m ~ 30d,自定义),所有 Cell 的 SQL 时间条件自动同步
- 自动刷新:支持 5 秒到 5 分钟多档间隔,满足实时监控场景
- 全屏模式:隐藏侧边栏,最大化可视面积
- 12 列网格布局:基于 react-grid-layout 的自由拖拽和缩放,Cell 尺寸可任意调整
- Cell 操作:悬停显示重命名、配置查询、删除按钮
每个 Cell 可绑定一条 SQL 查询,执行后以表格、折线图或柱状图渲染。点击"配置查询"跳转到数据探索器编辑 SQL,支持回传上下文。
连续查询 — CQ(Continuous Queries)
定期执行 SQL 并将结果写入目标 Measurement 的自动化任务管理。
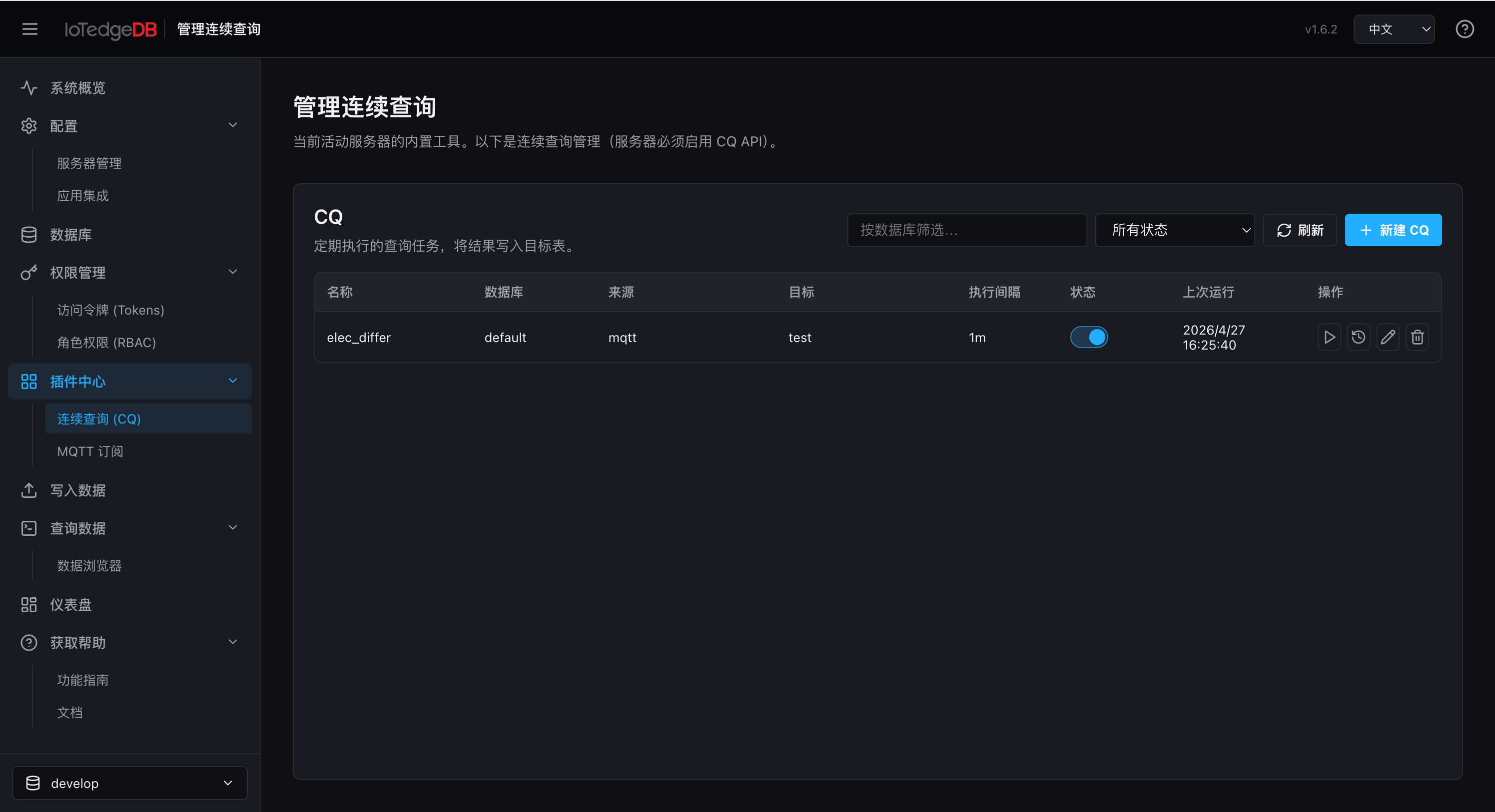
功能要点
- 创建 CQ:指定名称、数据库、源 Measurement、目标 Measurement、执行间隔(如
1h)、SQL 语句。SQL 中必须包含{start_time}和{end_time}占位符。平台提供模板自动生成。 - 启用/禁用:滑动开关实时切换,绿色为启用、灰色为停用
- 手动执行:点击 Play 按钮立即触发一次执行
- 执行历史:查看最近 30 次执行记录,包含状态、写入行数、耗时和错误信息
- 筛选:按数据库名筛选,按启用/禁用状态分类查看
- 可选参数:保留天数(Retention Days)、删除源数据天数(Delete Source After Days)
典型场景:每小时聚合传感器数据并写入汇总表,实现数据降采样和长期趋势分析。
MQTT 订阅(MQTT Subscriptions)
管理从 MQTT Broker 实时摄取数据到数据库的订阅任务。
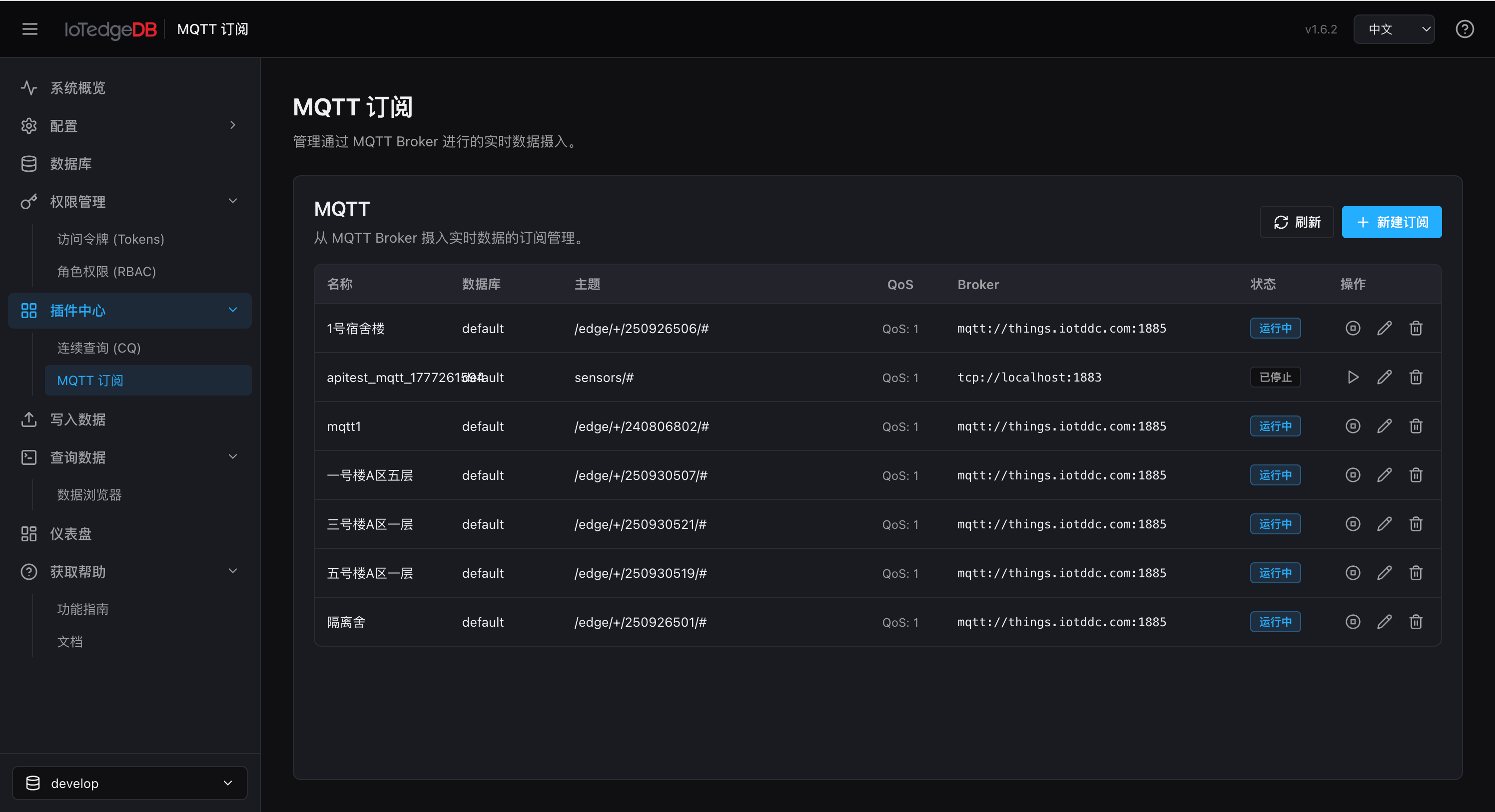
功能要点
- 创建订阅:填写名称、Broker URL(如
mqtt://localhost:1883)、Topic Filter(支持逗号分隔多个 Topic 及+通配符)、目标数据库、QoS 级别(0/1/2) - 启动/停止:Play 和 Stop 按钮控制订阅运行状态,状态标签颜色实时反馈(蓝色运行中、灰色已停止)
- 编辑/删除:修改订阅参数,删除前需先停止
- 自动启动:创建时可勾选 Auto Start,保存后立即可用
典型场景:配置 device/+/temperature 通配 Topic,自动将大量边缘设备上报的温度数据实时写入时序库,配合连续查询实现毫秒级降采样。
权限管理 — Token 与 RBAC
API Token 管理
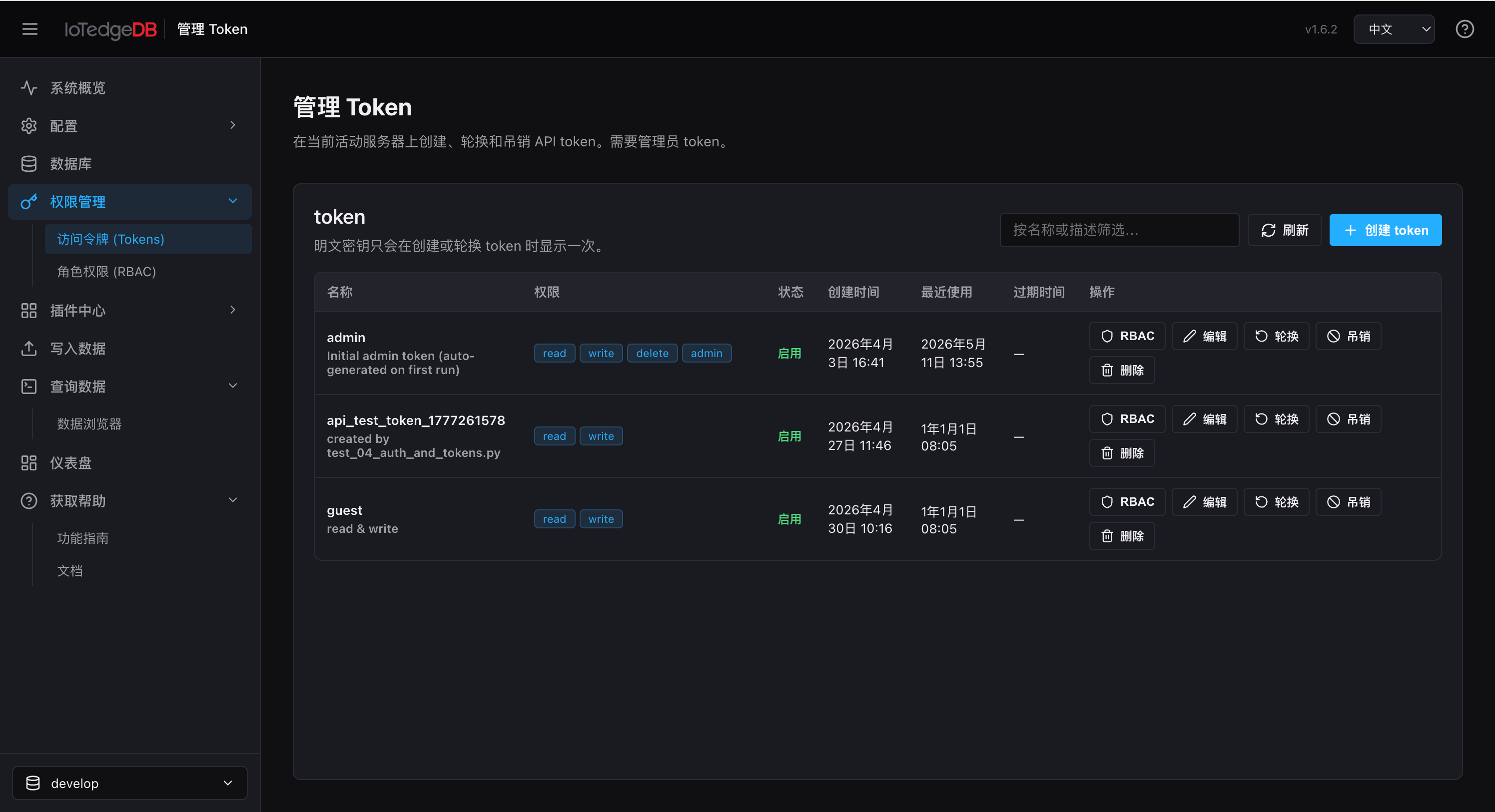
以表格形式进行 Token 全生命周期管理:
- 创建 Token:填写名称、描述,支持三种权限模式——
- 默认(Read + Write):全局读写
- 自定义:勾选 Read / Write / Delete / Admin 作用域
- 仅 RBAC:Token 自身无全局权限,完全由团队成员关系决定访问范围
- 过期时间:永不过期或 24h / 7d / 30d / 90d
- 轮换(Rotate):使旧密钥失效并签发新密钥,新值仅显示一次
- 吊销(Revoke):禁用但保留审计记录
- 密钥展示:创建/轮换后弹出一次性展示弹窗,提供"复制到剪贴板"按钮
RBAC 权限体系
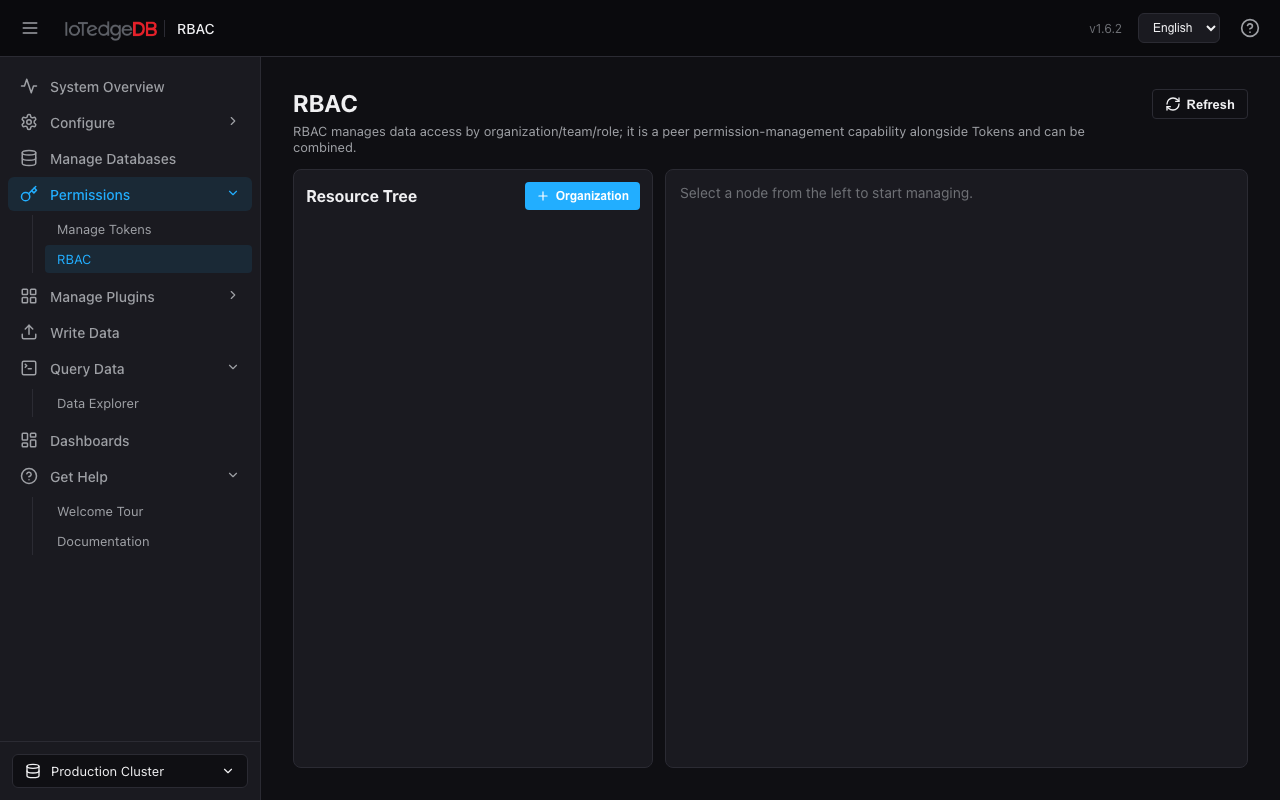
三级层级树管理数据访问权限:
组织(Organization)
└── 团队(Team)
└── 角色(Role)
└── 测量权限(Measurement Permission)
- 组织:顶级隔离单元,可创建多个组织
- 团队:组织内的协作单元,支持 Token 绑定向导
- 角色:绑定 database_pattern + 权限集(read/write/delete/admin)
- 测量权限:更细粒度的 measurement_pattern 级别控制
Token 绑定向导:三步式引导流程——选择 Token → 确认目标团队 → 预览生效权限 → 确认绑定。绑定后该 Token 自动获得对应团队和角色的数据访问权限。
应用集成(Integrations)
配置 AI 大模型以启用自然语言查询(NL2SQL)能力。
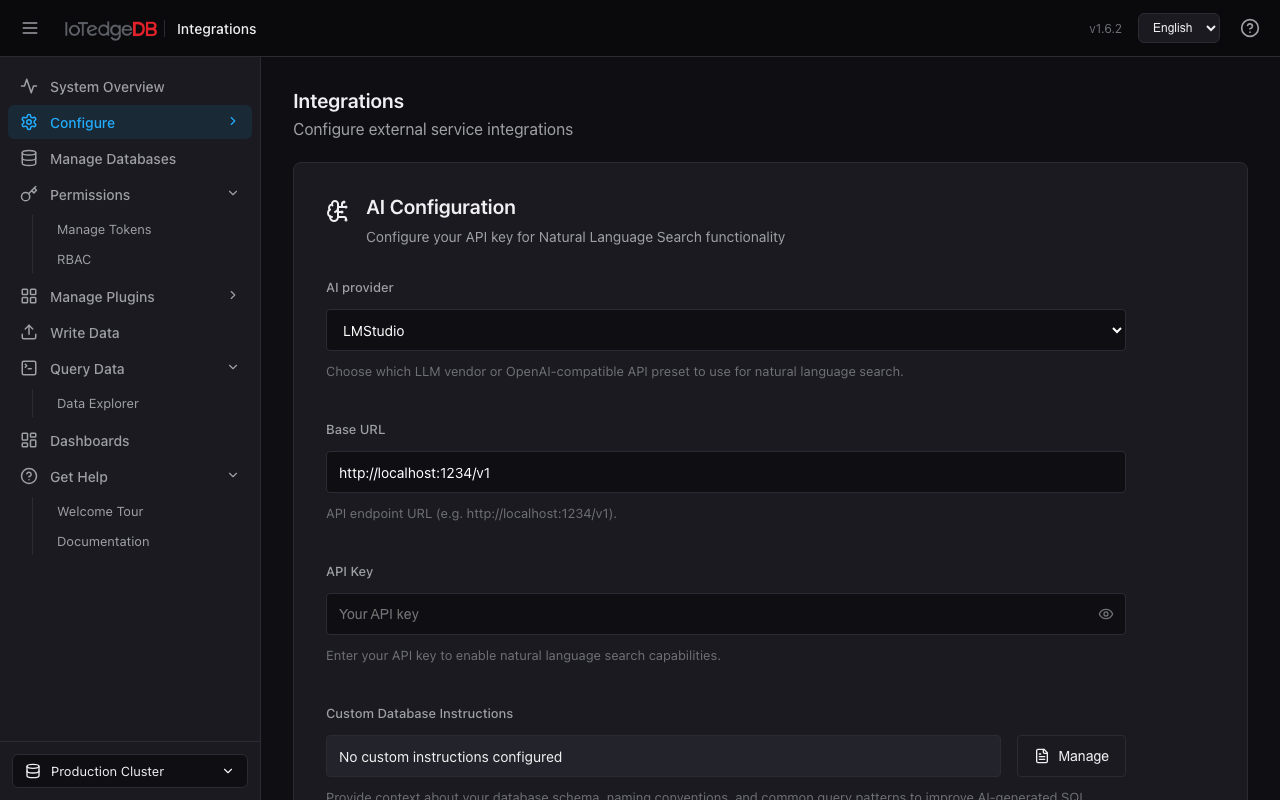
配置项
- AI 提供商:11 个选项(OpenAI / DeepSeek / 通义千问 / 智谱 GLM / Moonshot / 豆包 / 腾讯混元 / 百度千帆 / 讯飞星火 / LM Studio / 自定义),切换时自动填入默认 API 端点
- API Key:密码输入框,支持显隐切换
- Base URL:可覆盖 API 端点地址
- 自定义指令:引导 AI 生成符合项目需求的 SQL。支持直接编辑、上传
.txt/.md文件,或使用内置示例模板
配置保存后,在数据探索器的 Natural Language 模式中即可使用。
总结
IotEdge DB Explorer 的 12 个模块构成了一条从连接 → 建库 → 查询 → 写入 → 可视化 → 自动化 → 权限管控的完整工具链:
| 阶段 | 模块 | 核心能力 |
|---|---|---|
| 接入 | Servers | 多节点连接、Token 认证 |
| 建库 | Databases | 数据库 CRUD、Measurement 浏览 |
| 查询 | Data Explorer | SQL 编辑 + NL2SQL + 可视化 + 导出 |
| 摄入 | Write Data | 行协议 / CSV / Parquet + 示例数据 |
| 观察 | System Overview | 15 类运行时指标 + 时序趋势图 |
| 呈现 | Dashboards | 拖拽式布局 + 多源查询 + 自动刷新 |
| 自动化 | CQ / MQTT | 定时降采样 + 实时流摄取 |
| 管控 | Tokens / RBAC | Token 全生命周期 + 三级权限层级 |
| 智能 | Integrations | AI 大模型接入,赋能自然语言查询 |
无论你是运维人员巡检节点状态、数据工程师探索时序模式,还是平台管理员管控访问权限,IotEdge DB Explorer 都提供了对应的专业工具。
]]>